这是微服务治理的第一期。最近在家闲来无事,碰巧家中又有几台设备可供我折腾。对分布式服务管理的兴趣由来已久,就打算开这个坑了。这个系列的预期是前期参考诸多博客,做交叉验证;后期希望能结合一些自己的玩具项目的实践。事不宜迟,"Link start!"
文章中的一些符号:
#[...]:作者很不确定的观点
a->b:a 是事务,b 是子事务集合,表示 a 事务的成功/回退等于子事务们的一致成功/部分失败
我是废话:作者的碎碎念
微服务是单体服务拆分成若干子服务,并分配在不同域下所产生的概念。微服务间使用同步通信(rpc / http)/ 异步通信(消息队列)等网络方式进行交互,并且不一定需要根据服务的 ip + 端口进行访问(使用注册中心进行服务访问管理)。
服务拆分的好处在当下背景是显而易见的,技术层面上加强了可扩展性,对于技术栈也更加包容。缺点则是,#[繁多的分布式模式与潜在的业务侵入等问题使得服务部署启动和运维变得复杂]。
在有诸如 rpc 等基本的设备数据交互手段后,需要的就是服务间协同工作的手段,也就是分布式事务。
微服务理论
在讲解分布式事务前,先展开下微服务理论。单体服务的事务 ACID 不再赘述。在微服务领域,有 CAP 理论和 BASE 理论,“高屋建瓴”地用于指导分布式系统的设计。以下是两个理论的定义。
CAP 理论
CAP 理论指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、和分区容错性(Partition Tolerance)这三个特性无法同时得到保证。在任何分布式系统中,当遇到网络分区的时候,就必须在一致性和可用性之间做出权衡。
- 一致性(Consistency):所有节点在同一时间具有相同的数据视图。即当一个节点更新了数据,其他节点读取这个数据时能够立即看到最新的变化。跟数据库 ACID 的 C 不同,数据库的 C 表述约束条件(唯一键、外键、表里自建的约束等...),事务后要保持正确。
(什么文科考试) - 可用性(Availability):服务 A, B, C 节点中其中某一节点集合宕机,不影响另外的节点对外提供服务。可用性强调非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应,与分区容忍性做区分)。只有非故障节点才能满足可用性要求,如果节点本身就故障了,发给节点的请求不一定能得到一个响应。不能超时、不能出错,结果是合理的。注意没有说“正确”的结果。例如,应该返回 100 但实际上返回了 90,肯定是不正确的结果,但可以是一个合理的结果(比如 90 是旧数据)。
- 分区容忍性(Partition Tolerance):当出现网络分区后,系统能够继续“履行职责”。只要是网络分区现象,不管是什么原因,就通通算在里面。可能是丢包,也可能是连接中断,还可能是拥塞等。
仔细品味 CAP 理论,其实分区容忍性应当是可用性的子集。不过分区容忍性将网络层面的特性提取了出来,某种程度让该理论进阶到了分布式服务,而非单体服务。
在微服务架构中,通常选择在分区容忍性和可用性之间做出权衡,因为分布式系统难免会面临网络分区的情况。也就是 P 必选,在 C 和 A 中做抉择。
注意,CAP 关注的对数据的读写操作,而不是分布式系统的所有功能。例如,raft 的选举机制就不是 CAP 探讨的对象。
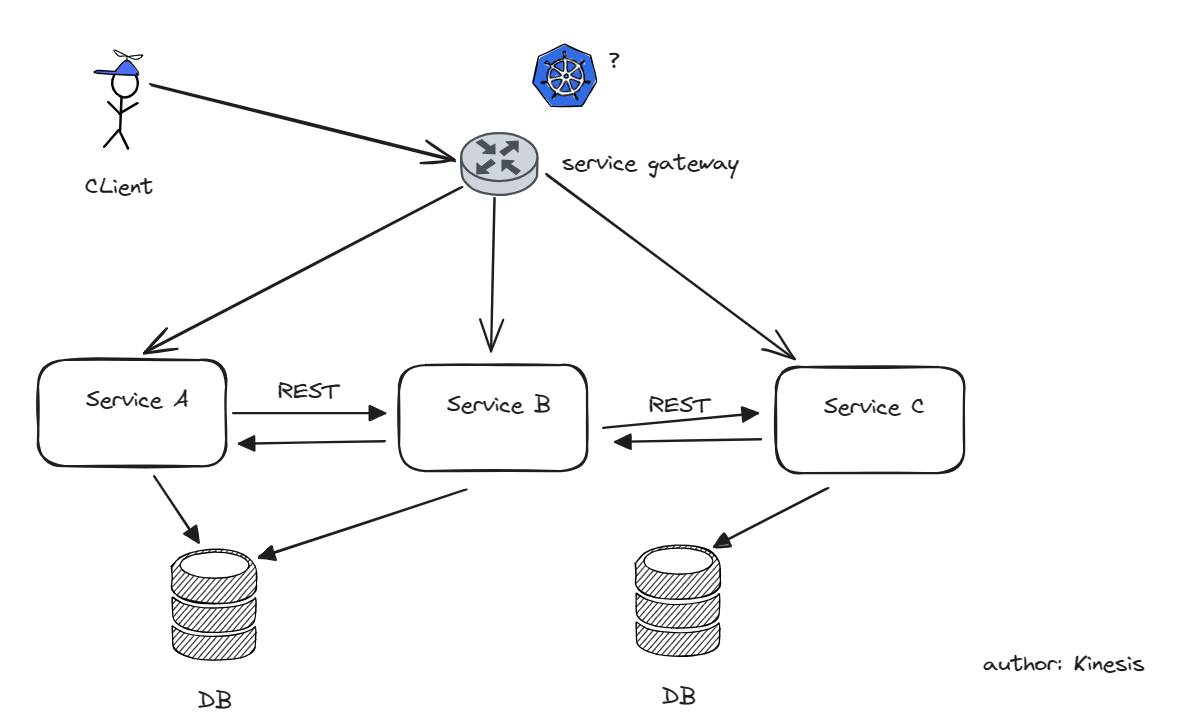
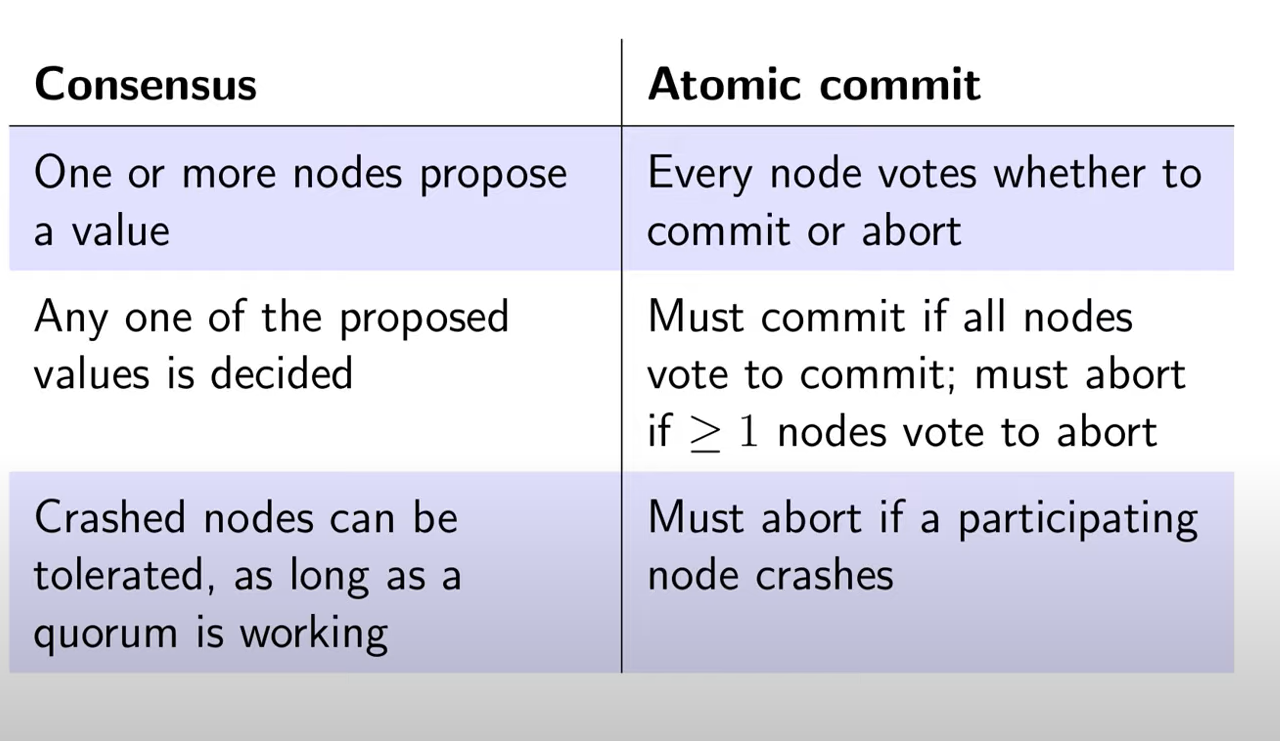
在后续的系列中,我会把 raft 这类共识算法叫做分布式一致性算法,维护事务的叫分布式事务。具体的区别可看下面这张图。
坑点:
-
适用场景:分布式系统有很多类型,有异构的,比如节点之间是上下游依赖的关系,有同构的,比如分区 / 分片型的、副本型的(主从、多主)。CAP 在不同场景下的理解应有所不同(以下是 *gpt 的回答)。
- 异构系统:在异构系统中,节点之间的功能和角色可能不同,有上下游的依赖关系。系统设计者需要在不同类型的节点之间权衡一致性、可用性和分区容忍性。例如,可以在上游节点强调一致性,而在下游节点强调可用性。
- 同构系统:在同构系统中,节点通常具有相似的功能和角色。设计者需要权衡不同的同构节点之间的一致性、可用性和分区容忍性。例如,在分区/分片型系统中,通常会牺牲一致性以获得更高的可用性。在副本型系统中,可以强调一致性来确保数据的准确性。
- 多主系统:多主系统中,多个节点都可以接收写操作。设计者需要考虑如何在多主环境中实现一致性,以及如何应对网络分区。
- 主从系统:在主从系统中,一个节点是主节点,负责接收写操作,而其他节点是从节点,用于读取数据。需要考虑如何在主从系统中实现高可用性和分区容忍性,同时保持数据的一致性。
-
一致性的概念,从强到弱,线性一致性、顺序一致性、因果一致性、单调一致性、最终一致性,CAP 中的一致性应该是指顺序一致性。
-
CAP 中的一致性,与 ACID 中的一致性的区别。事务中的一致性,是指满足完整性约束条件,CAP 中的一致性,是指读写一致性(不同节点)。
-
CAP 中的可用性,与我们常说的高可用的区别。比如 HBase、MongoDB 属于 CP 架构,Cassandra、CounchDB 属于 AP 系统,能说后者比前者更高可用么?应该不是。CAP 中的可用性,是指在某一次读操作中,即便发现不一致,也要返回响应,即在合理时间内返回合理响应。我们常说的高可用,是指部分实例挂了,能自动摘除,并由其它实例继续提供服务,关键是冗余。
需要强调的是,CAP 关注的粒度是数据,而不是整个系统。C 与 A 之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户而有所不同。所以不是系统决策上选择 C 还是 A,而是具体业务数据上选择 C 还是 A。
以一个最简单的用户管理系统为例,用户管理系统包含用户账号数据(用户 ID、密码)、用户信息数据(昵称、兴趣、爱好、性别、自我介绍等)。通常情况下,用户账号数据会选择 CP,而用户信息数据会选择 AP,如果限定整个系统为 CP,则不符合用户信息数据的应用场景;如果限定整个系统为 AP,则又不符合用户账号数据的应用场景。
所以在 CAP 理论落地实践时,需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
另外,CAP 是忽略网络延迟的。这是一个非常隐含的假设,在定义 CAP 的一致性时,并没有将延迟考虑进去。也就是说,当事务提交时,数据能够瞬间复制到所有节点。但实际情况下,从节点 A 复制数据到节点 B,总是需要花费一定时间的。如果是相同机房,耗费时间可能是几毫秒;如果是跨地域的机房,例如北京机房同步到广州机房,耗费的时间就可能是几十毫秒。这就意味着,CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点 A 和节点 B 的数据并不一致。
不要小看了这几毫秒或者几十毫秒的不一致,对于某些严苛的业务场景,例如和金钱相关的用户余额,或者和抢购相关的商品库存,技术上是无法做到分布式场景下完美的一致性的。而业务上必须要求一致性,因此单个用户的余额、单个商品的库存,理论上要求选择 CP 而实际上 CP 都做不到,只能选择 CA。也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入。
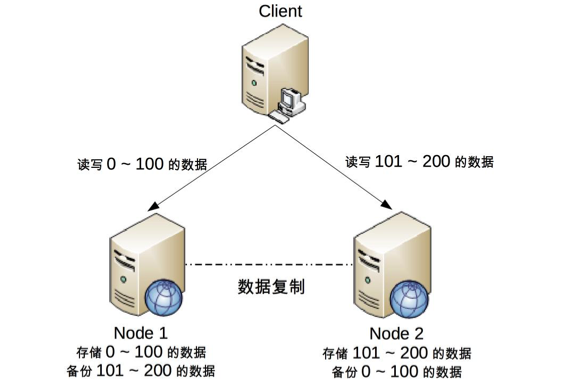
需要注意的是,这并不意味着这类系统无法应用分布式架构,只是说“单个用户余额、单个商品库存”无法做分布式,但系统整体还是可以应用分布式架构的。例如,下面的架构图是常见的将用户分区的分布式架构。
我们可以将用户 id 为 0 ~ 100 的数据存储在 Node 1,将用户 id 为 101 ~ 200 的数据存储在 Node 2,Client 根据用户 id 来决定访问哪个 Node。对于单个用户来说,读写操作都只能在某个节点上进行;对所有用户来说,有一部分用户的读写操作在 Node 1 上,有一部分用户的读写操作在 Node 2 上。
这样的设计有一个很明显的问题就是某个节点故障时,这个节点上的用户就无法进行读写操作了,但站在整体上来看,这种设计可以降低节点故障时受影响的用户的数量和范围,毕竟只影响 20% 的用户肯定要比影响所有用户要好。这也是为什么挖掘机挖断光缆后,支付宝只有一部分用户会出现业务异常,而不是所有用户业务异常的原因。
一般早期的系统不存在 CP 和 AP 的选择,可以同时满足 CA。
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
同样以用户管理系统为例,即使是实现 CA,不同的数据实现方式也可能不一样:用户账号数据可以采用“消息队列”的方式来实现 CA,因为消息队列可以比较好地控制实时性,但实现起来就复杂一些;而用户信息数据可以采用“数据库同步”的方式来实现 CA,因为数据库的方式虽然在某些场景下可能延迟较高,但使用起来简单。
放弃并不等于什么都不做,需要为分区恢复后做准备。
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么都不做。实际上,CAP 理论的“牺牲”只是说在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。
例如,99.99% 可用性(俗称 4 个 9)的系统,一年运行下来,不可用的时间只有 50 分钟;99.999%(俗称 5 个 9)可用性的系统,一年运行下来,不可用的时间只有 5 分钟。分区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态。
最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到 CA 状态。
同样以用户管理系统为例,对于用户账号数据,假设我们选择了 CP,则分区发生后,节点 1 可以继续注册新用户,节点 2 无法注册新用户(这里就是不符合 A 的原因,因为节点 2 收到注册请求后会返回 error),此时节点 1 可以将新注册但未同步到节点 2 的用户记录到日志中。当分区恢复后,节点 1 读取日志中的记录,同步给节点 2,当同步完成后,节点 1 和节点 2 就达到了同时满足 CA 的状态。
而对于用户信息数据,假设我们选择了 AP,则分区发生后,节点 1 和节点 2 都可以修改用户信息,但两边可能修改不一样。例如,用户在节点 1 中将爱好改为“旅游、美食、跑步”,然后用户在节点 2 中将爱好改为“美食、游戏”,节点 1 和节点 2 都记录了未同步的爱好数据,当分区恢复后,系统按照某个规则来合并数据。例如,按照“最后修改优先规则”将用户爱好修改为“美食、游戏”,按照“字数最多优先规则”则将用户爱好修改为“旅游,美食、跑步”,也可以完全将数据冲突报告出来,由人工来选择具体应该采用哪一条。
BASE理论
BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency),核心思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
-
基本可用(Basically Available)
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
这里的关键词是“部分”和“核心”,具体选择哪些作为可以损失的业务,哪些是必须保证的业务,是一项有挑战的工作。例如,对于一个用户管理系统来说,“登录”是核心功能,而“注册”可以算作非核心功能。因为未注册的用户本来就还没有使用系统的业务,注册不了最多就是流失一部分用户,而且这部分用户数量较少。如果用户已经注册但无法登录,那就意味用户无法使用系统。例如,充了钱的游戏不能玩了、云存储不能用了……这些会对用户造成较大损失,而且登录用户数量远远大于新注册用户,影响范围更大。
-
软状态(Soft State)
允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
-
最终一致性(Eventual Consistency)
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
这里的关键词是“一定时间” 和 “最终”,“一定时间”和数据的特性是强关联的,不同的数据能够容忍的不一致时间是不同的。举一个微博系统的例子,用户账号数据最好能在 1 分钟内就达到一致状态,因为用户在 A 节点注册或者登录后,1 分钟内不太可能立刻切换到另外一个节点,但 10 分钟后可能就重新登录到另外一个节点了;而用户发布的最新微博,可以容忍 30 分钟内达到一致状态,因为对于用户来说,看不到某个明星发布的最新微博,用户是无感知的,会认为明星没有发布微博。“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。前面在剖析 CAP 理论时,提到了其实和 BASE 相关的两点:CAP 理论是忽略延时的,而实际应用中延时是无法避免的。
这一点就意味着完美的 CP 场景是不存在的,即使是几毫秒的数据复制延迟,在这几毫秒时间间隔内,系统是不符合 CP 要求的。因此 CAP 中的 CP 方案,实际上也是实现了最终一致性,只是“一定时间”是指几毫秒而已。AP 方案中牺牲一致性只是指分区期间,而不是永远放弃一致性。这一点其实就是 BASE 理论延伸的地方,分区期间牺牲一致性,但分区故障恢复后,系统应该达到最终一致性。
综合上面的分析,ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
分布式事务场景
CAP/BASE 理论后,该介绍相关的分布式事务场景实例了。
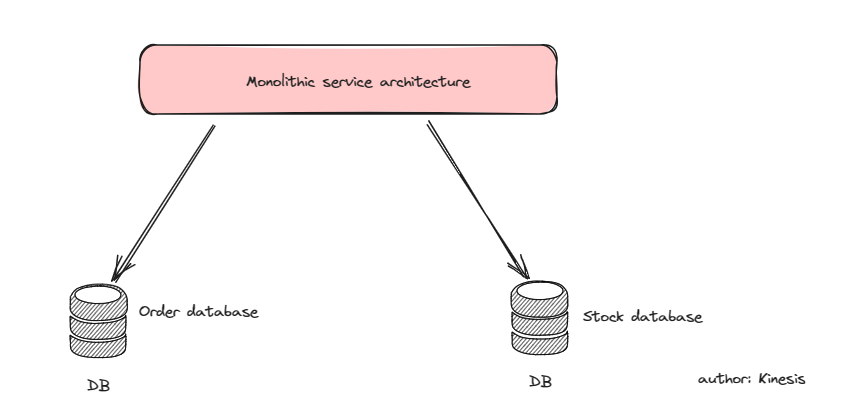
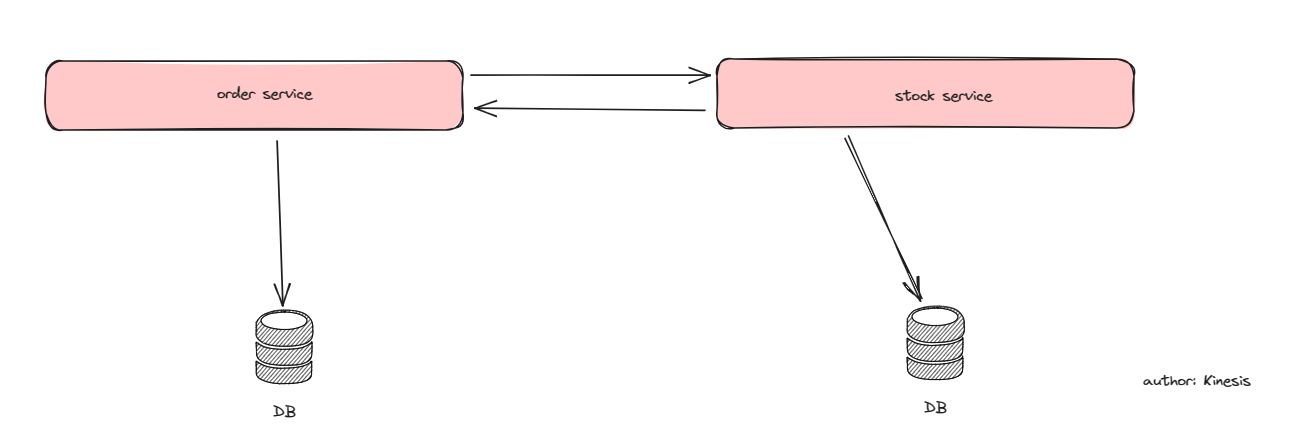
场景1-单体架构,但是分库
在如下图的单体架构中,订单和库存的库是分开的,需要在单体服务里完成分布式事务(完成订单->有库存+创建新订单)。
场景2-分布式服务,但是单库
存在两个服务的相互调用(如果不存在的话,交给数据库的读写锁就好了)。
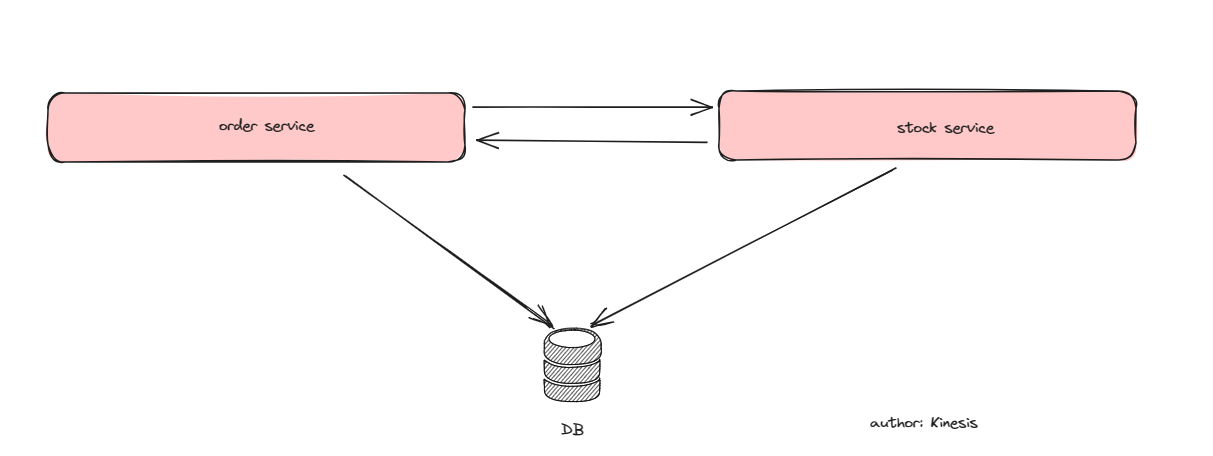
场景3-分布式服务,服务互相调用
分布式事务解决方案
回溯一下历史,最早的分布式事务控制协议,即全局事务,是由 Tuxedo 首先提出的(实际这里表述不准确,全局事务理论首先在理论界提出,Tuxedo 是早期首先实现的一批应用)。
Tuxedo 的历史。太长不看版:Tuxedo 诞生于 1980 年代,初衷是为 UNIX 系统提供事务处理,而后发展到支持分布式操作。被 Oracle 后,目前仍有持续更新,据说支持 k8s。
*gpt4 的回答:Tuxedo (Transaction for UNIX, Extended for Distributed Operations) 是一个具有悠久历史的中间件平台,旨在提供强大的分布式事务处理能力。以下是 Tuxedo 的主要历史节点:
- 早期发展:
- Tuxedo 最初是在 1980 年代由 AT&T 开发的。它最初的目的是为 UNIX 系统提供事务处理能力,随着时间的推移,它的功能得到了扩展,以支持分布式操作。
- Novell的收购:
- 在 1993 年,Novell 公司收购了 AT&T 的 UNIX System Laboratories,包括 Tuxedo。此后,Tuxedo 开始支持更多的操作系统和硬件平台。
- BEA Systems的收购:
- 在1996年,BEA Systems 收购了 Novell 的 Tuxedo 资产,并继续开发和推广 Tuxedo 产品。在BEA Systems 的管理下,Tuxedo成为了业界领先的分布式事务处理中间件之一。
- Oracle的收购:
- 在2008年,Oracle 公司收购了 BEA Systems,从而也获得了 Tuxedo 的所有权。自那时以来,Oracle 一直在维护和更新 Tuxedo,使其保持了与现代技术的兼容性和相关性。
- 最近的更新:
- 如前所述,最新版本的 Oracle Tuxedo 22c(版本 22.1.0.0.0)包括了许多新特性和增强功能,特别是对 Kubernetes 和基于云的部署的支持[1](https://blogs.oracle.com/database/post/announcing-oracle-tuxedo-22c#:~:text=Oracle is pleased to announce,Kubernetes and Cloud Based Deployments)。
Tuxedo 的历史展示了它如何从一个基本的 UNIX 事务处理系统发展成为一个支持复杂分布式操作的强大中间件平台。随着不同公司的收购和技术的进步,Tuxedo 不断地适应并满足了现代分布式系统的需求。
全局事务的最早的一个实例是二阶段提交 2pc (two phase commit),也常用 XA (eXtended Architecture) 表述。
XA 模式等于 2pc,或者 XA 的实现流程表征为二阶段提交。具体可参考文末 reference。
2pc/XA
2pc 基于 DTP 模型实现。在 DTP 模型中,分布式事务由三个角色:
- AP (Application):微服务
- TM (Transaction Manager):事务管理器
- RM (Resource Manager):资源管理器
你可能会说:等等,这都是什么角色。不用着急,先忽略上面的角色,来看看你的系统(client)是如何用 2pc 解决分布式事务的。
client 想要发起一个事务 tx(tx->tx_A+tx_B),首先发给 db A,B 标识符 T1,让 A,B 开始对应的事务 tx_A、tx_B,完成对应的逻辑,但暂时不落盘到各自的磁盘里。
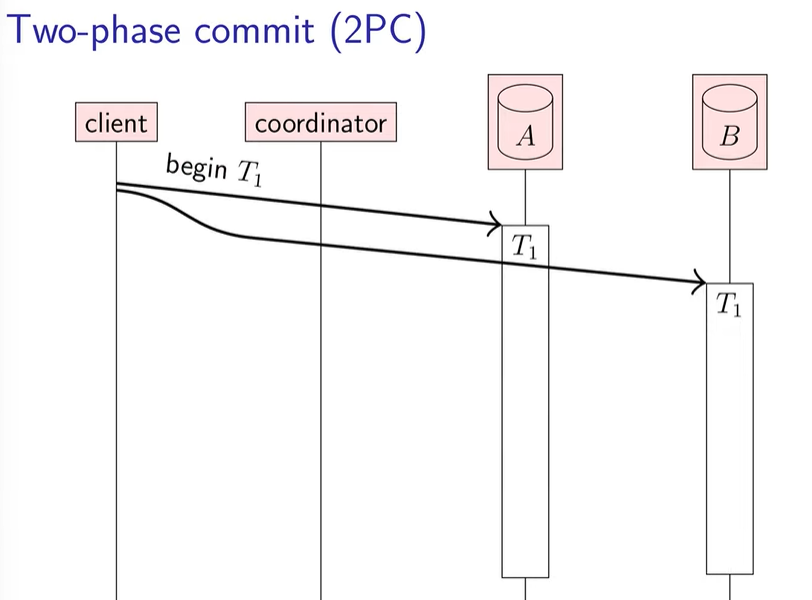
蓝色的部分就是 A,B 完成事务逻辑的基本过程。
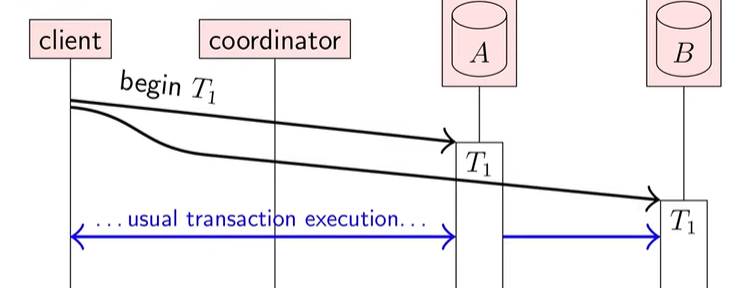
随即 client 发送 commit T1 指令,让 Transaction coordinator(client 的提交代理)去处理后续事务提交问题。也就是说,client 在 begin T1 开启事务瞬间就可以向 coordinator 发包,让 coordinator 代理提交了。
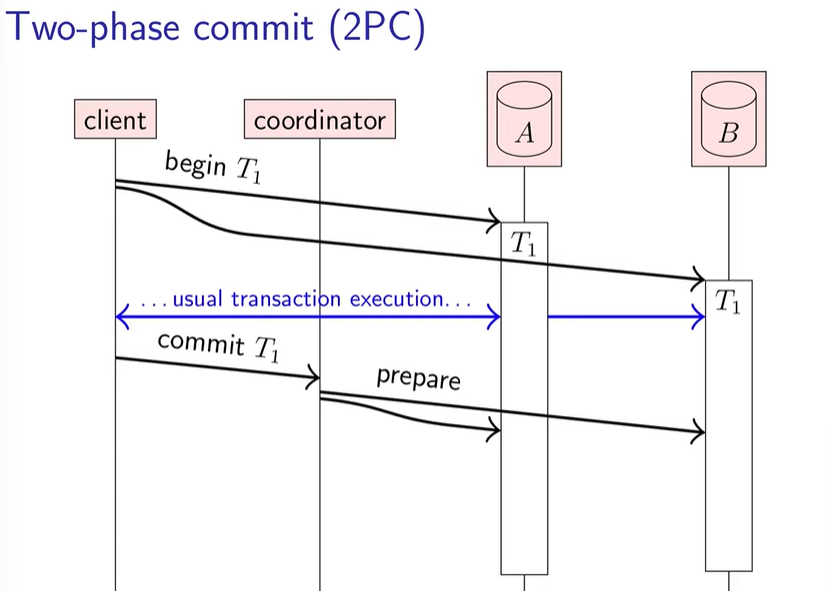
prepare 是承诺请求。db 收到 prepare 就得往硬盘写数据了,并且保持数据的一致性(ACID 的 C,即满足一致性约束),但不提交。
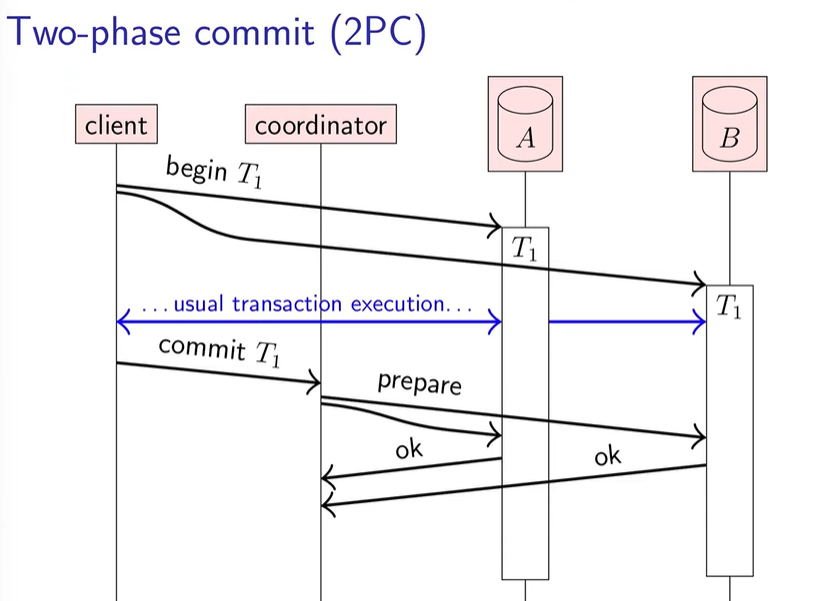
只要 db 回应 ok,这样就相当于 db 给 coordinator 说:只要你下令,我一定可以提交成功。coordinator 确定了所有子事务都确保能完成后,便向所有的 db 发出 commit,然后完成。
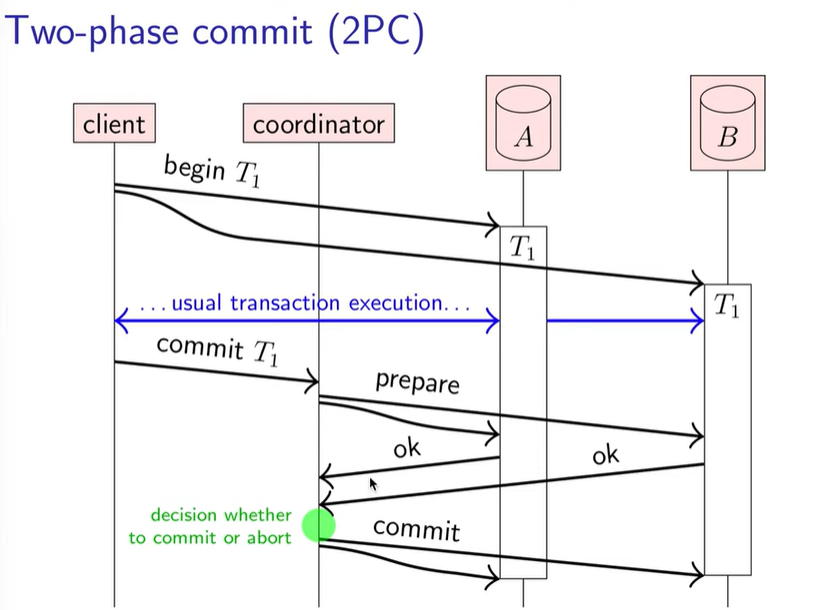
让我们继续讨论边界情况:
- 数据库炸了。2pc 是能覆盖该边界情况的。体现在 prepare 发出后没有收到 ok 的 timeout。
- coordinator 炸了。首先 coordinator 在向 db 发 commit/abort 前,会向自己的 disk 写命令 log,即当前事务的决策 dm = commit|abort。如果连命令 log 都没写(也就是落盘决策前就挂机了),那么恢复后会向所有 db 发出 abort;如果已经做了决策 dm(在 log 中有记录),那会再次向所有 db 发送 dm(因为这里还有一个子边界情况,即已经向部分 db 发送了 dm。为了保证一致性,coordinator 恢复后必然要发送相同的 dm)。
所以 2pc 的问题也在第二个边界情况。当给 db 发送了 prepare 的 coordinator 炸了后,db 是无法自行决定是否完成 commit 的,处在 blocked 的状态(如果自行决定,不管用什么超时之类的决策,都会破坏事务的原子性)。
但是!这也是有解决办法的,具体见 Martin Kleppmann 这视频 12:57 提到的 Fault-tolerant two-phase commit。该算法使用了全序广播(total order broadcast),来统筹每个节点的 vote,决定是否 abort/commit。算法流程略,视频中有提到。
total order broadcast 在 Martin Kleppmann 课的 [4.2 节有详细介绍](Distributed Systems 4.2: Broadcast ordering - YouTube)。在广播算法的约束较严格(最严格的是 FIFO-total order broadcast),但除了传输效率外有限制,有额外的 bonus。
但是在中文互联网貌似没找到应用该算法的实例框架。
回到 DTP 模型,coordinator 其实就是 TM,数据库 db 的大脑就是 RM(比如 MySQL 的 innoDB),client 就是 AP。当然不同框架的 DTP 模型耦合类型不同,根据具体的框架决定。
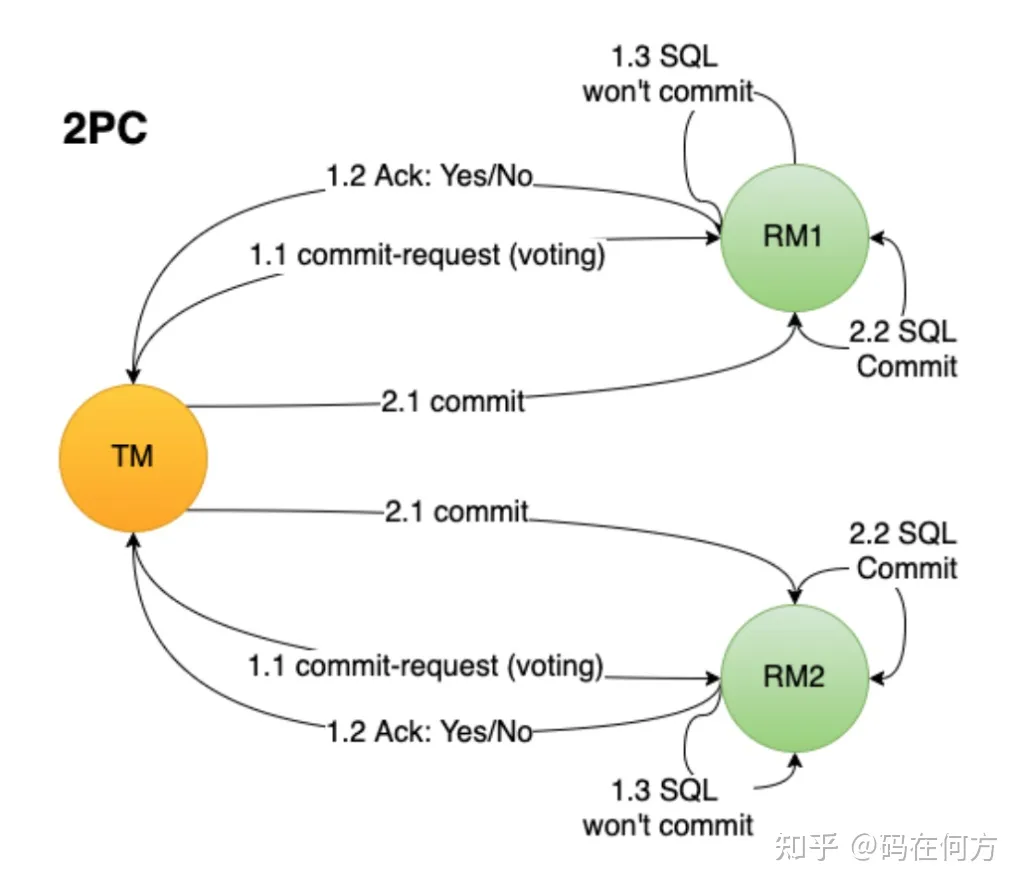
另外还有一个 3pc 方案,解决了一点 coordinator 故障问题,但是引来一些其他问题,也不是主流解决方案,这里不再提及。
TCC 和消息事务、最大努力通知三个模式
咕咕咕(反正也很简单。另外下面 seata 实践用的是 AT 模式,阿里团队的作品。跟 XA 很相似,所以不妨碍入门 Seata)
Seata
Seata概念
既然分布式事务处理起来这么麻烦,那能不能让分布式事务处理起来像本地事务那么简单。而阿里巴巴团队发起了开源项目 Seata(Simple Extensible Autonomous Transaction Architecture) 。这是一套分布式事务解决方案,意在解决开发人员遇到的分布式事务各方面的难题。
Seata 的设计目标是对业务无侵入,因此它是从业务无侵入的两阶段提交(全局事务)着手,在传统的两阶段上进行改进,他把一个分布式事务理解成一个包含了若干分支事务的全局事务。而全局事务的职责是协调它管理的分支事务达成一致性,要么一起成功提交,要么一起失败回滚。
Seata 组成
我们看下 Seata 中存在几种重要角色:
- TC(Transaction Coordinator):事务协调者。管理全局的分支事务的状态,用于全局性事务的提交和回滚。
- TM(Transaction Manager):事务管理者。用于开启、提交或回滚事务。
- RM(Resource Manager):资源管理器。用于分支事务上的资源管理,向 TC 注册分支事务,上报分支事务的状态,接收 TC 的命令来提交或者回滚分支事务。
这是一种很巧妙的设计,我们来看图:
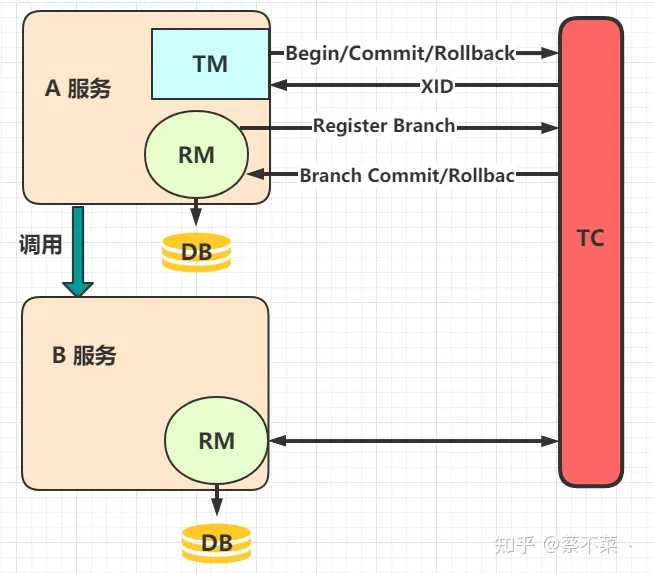
执行流程是这样的:
- 服务A中的 TM 向 TC 申请开启一个全局事务,TC 就会创建一个全局事务并返回一个唯一的 XID
- 服务A中的 RM 向 TC 注册分支事务,然后将这个分支事务纳入 XID 对应的全局事务管辖中
- 服务A开始执行分支事务
- 服务A开始远程调用B服务,此时 XID 会根据调用链传播
- 服务B中的 RM 也向 TC 注册分支事务,然后将这个分支事务纳入 XID 对应的全局事务管辖中
- 服务B开始执行分支事务
- 全局事务调用处理结束后,TM 会根据有误异常情况,向 TC 发起全局事务的提交或回滚
- TC 协调其管辖之下的所有分支事务,决定是提交还是回滚
Seata使用
我们从上面了解到了 Seata 的组成和执行流程,我们接下来就来实际的使用下 Seata。
Seata 有 AT、TCC、Saga、XA 模式,演示的是 AT 也就是默认推荐模式。emm其他的模式,有一说一,官方文档资料不是很足的样子(看来是力捧自己团队的 AT 模式了)
示例演示
我们简单创建了一个微服务项目(Spring boot+maven),其中有订单服务和库存服务。
我们这里采用了 nacos 作为注册中心,分别启动两个服务,我们在 nacos 控制台可以看到两个已经注册的服务:

如果对nacos还不熟悉的同学可以跳转查看这人的 nacos讲解:微服务新秀之Nacos
要提醒的是,Nacos 默认是集群启动。把他改成单机启动
startup.cmd -m standalone实际 nacos 就是当注册中心用,没别的。
我们接着创建了一个数据库,其中有两张表:c_order 和 c_product,其中商品表中有一条数据,而订单表中还未有数据,接下来我们将要对其进行操作!

我们现在模拟一个下单的过程:
- 请求进来,通过商品 pid 往数据库中查商品的信息
- 创建一条该商品的订单
- 对应扣减该商品的库存量
- 流程结束
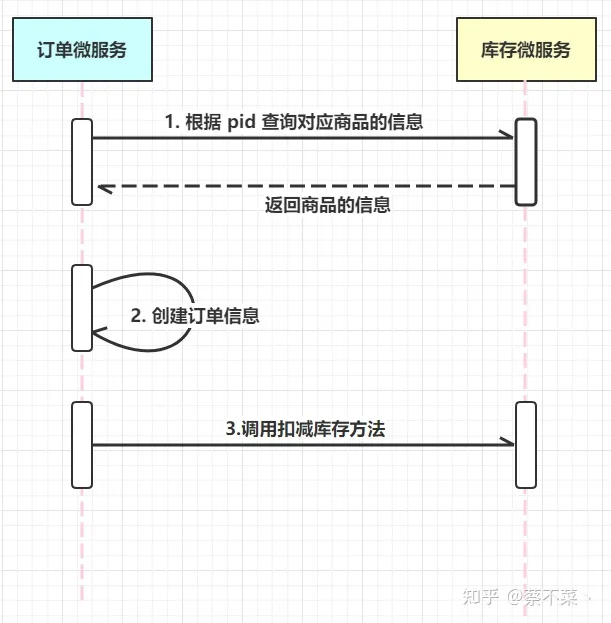
我们接下来就进入代码演示一下:
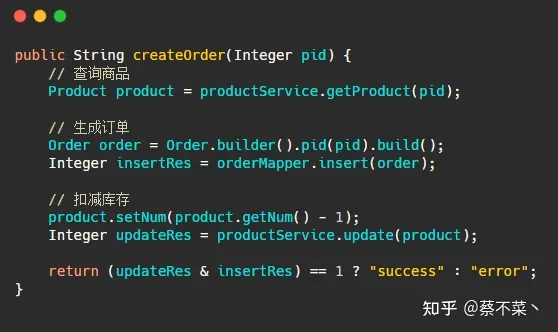
注意:这里 ProductService 并非是库存服务里面的类,而是利用 Feign 远程调用库存服务的接口
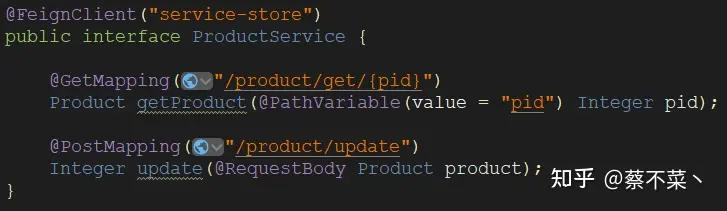
代码三步走,正常请况下肯定是没有问题的:
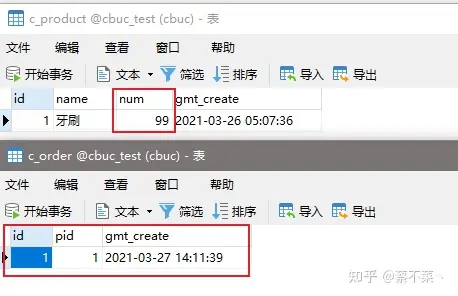
订单生成,库存也对应减少,感觉自己代码可以上线进入正轨的时候,我们来模拟一下库存中的异常,库存商品数量归为 100,订单表清空:

我们继续发送下单请求,可以看到库存服务已经抛出了异常

正常来说这个时候,库存表数量不应该减少,订单表不应该插入订单数据,但是事实真的是这样的吗?我们看数据:
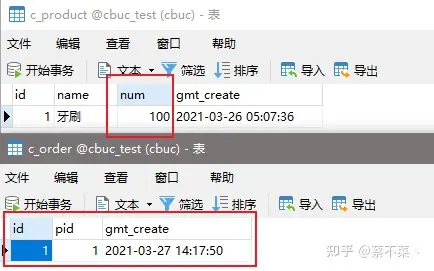
库存数量没减,但是订单却增加了。好了,到这里,你就已经见识到了分布式事务的灾难性危害。接下来主角登场!
Seata 安装
我们首先需要点击**下载地址**进行下载 Seata。
由于我们是使用 nacos 作为服务中心和配置中心,因此我们下载解压后需要做一些修改操作
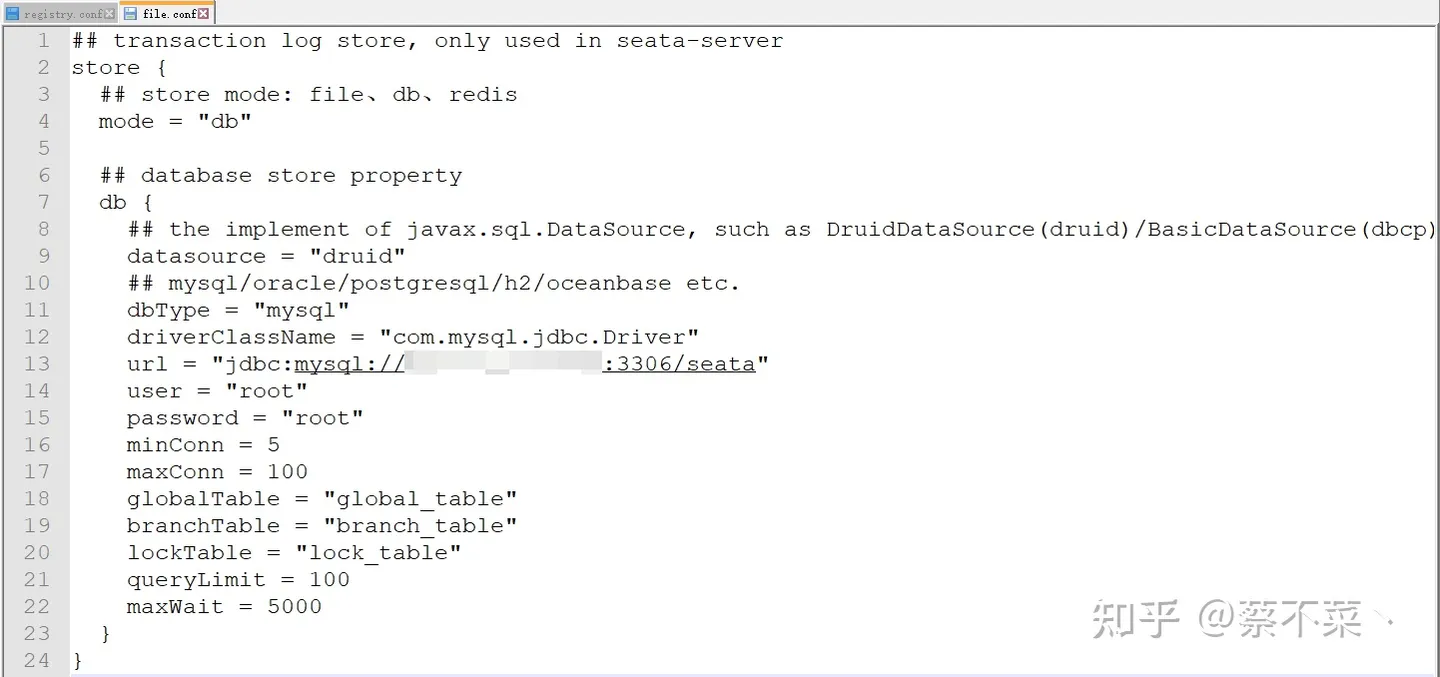
- 进入
conf目录编辑registry.conf和file.conf两个文件,编辑后内容如下:

- 由于新版 Seata 中没有
nacos-conf.sh和config.txt两个文件,因此我们需要独立下载:
我们需要将 config.txt 文件放到 seata 目录下,而非 conf 目录下,并且需要修改 config.txt 内容
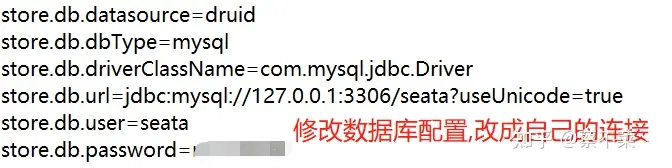
config.txt就是seata各种详细的配置,执行nacos-config.sh即可将这些配置导入到nacos,这样就不需要将file.conf和registry.conf放到我们的项目中了,需要什么配置就直接从nacos中读取。
- 执行导入
在 conf 目录下打开 git bash 窗口,执行以下命令:
sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t namespace-id(需要替换) -u nacos -w nacos
操作结束后,我们便可以在 nacos 控制台中看到配置列表,日后配置有需要修改便可以直接从这边修改,而不用修改目录文件:
- 数据库配置
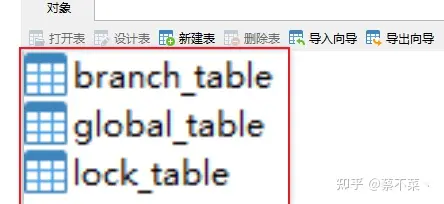
在 1.4.1 最新版中依然没有 sql 文件,所以我们还是需要另外下载:sql 下载地址
在 seata 数据中执行这个文件,生成三张表:
在我们的业务数据库中执行 undo_log 这张表:
CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
- 添加 log 文件
如果我们没有log输出文件,启动 seata 可能会报错,因此我们需要在 seata 目录下创建 logs 文件夹,在 logs 文件下创建 seata_gc.log 文件

- 启动
做好了以上准备,我们便可以启动 seata 了,直接在 bin 目录下 cmd 执行 bat 脚本即可,启动结束便可在 nacos 中看到 seata 服务:

Seata 集成
在 Seata 安装的步骤中我们便完成了 Seata 服务端 的启动安装,接下来就是在项目中集成 Seata 客户端
- 第一步:我们需要在 pom.xml 文件中添加两个依赖:
seata 依赖和nacos 配置依赖
<!--nacos-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!-- 排除依赖 指定版本和服务器端一致 -->
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
</exclusion>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.4.1</version>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.4.1</version>
</dependency>
注意: 这里需要排除 spring-cloud-starter-alibaba-seata 自带的 seata 依赖,然后引入我们自己需要的 seata 版本,如果版本不一致启动时可能会造成 no available server to connect 错误!
- 第二步:我们需要把
restry.conf文件复制到项目的 resource 目录下

- 第三步:需要自己配置seata代理数据源
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Primary
@Bean
public DataSourceProxy dataSource(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
配置完数据源我们得在启动类的 SpringBootApplication 上排除Druid数据源依赖,否则可能会出现循环依赖的错误:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
- 第四步:在 nacos 的配置文件控制台中加入我们服务的事务组项:
service.vgroupMapping + 服务名称 = default
group为: SEATA_GROUP
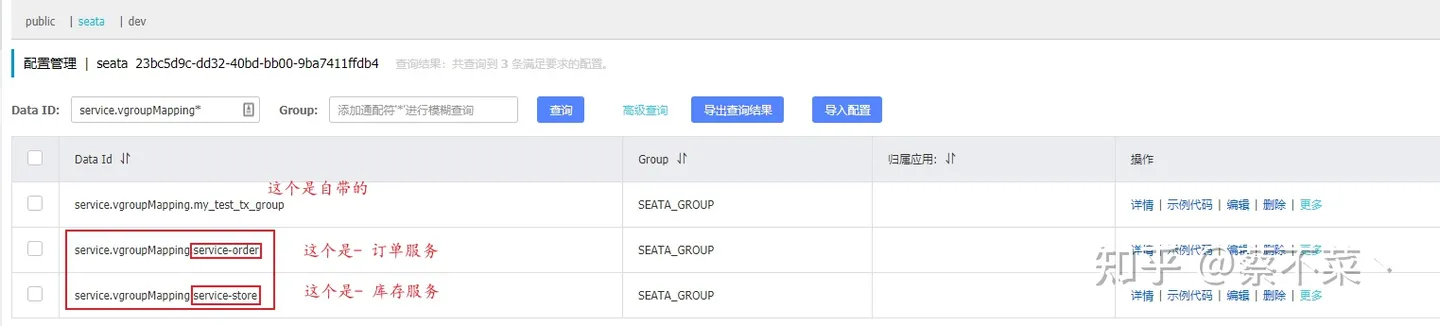
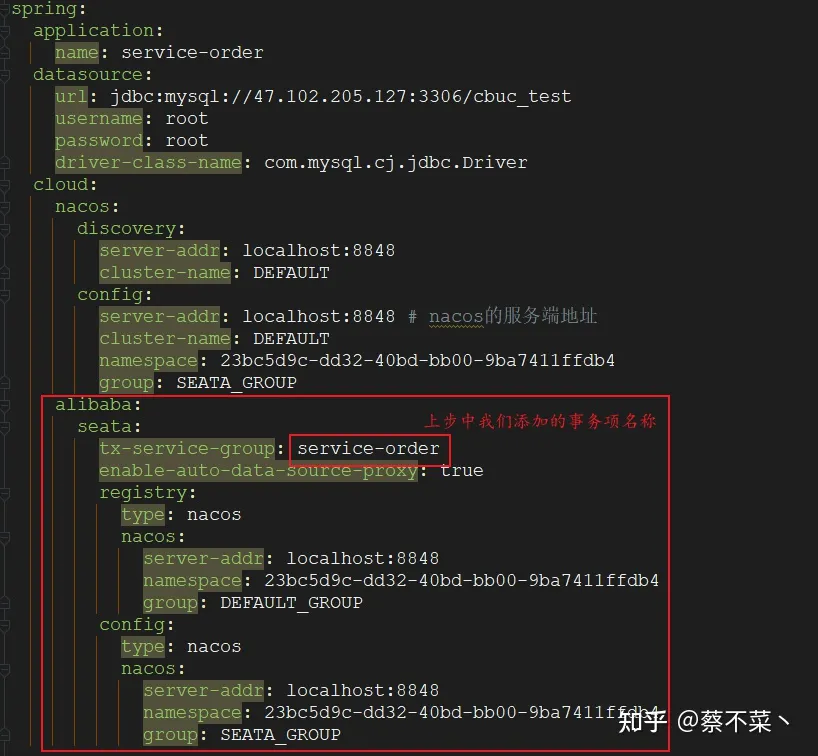
- 第五步:项目中配置修改
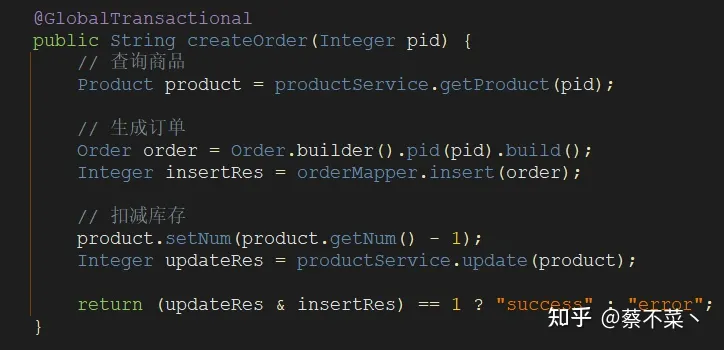
- 第六步:开启全局事务
这步就是最终一步了,在我们需要开启事务的方法上添加 @GlobalTransactional 注解,类似于我们单体事务添加的@Transactional
Seata 测试
我们现在回到项目中,在上面的示例演示中,我们已经知道了如果库存服务发生异常,会出现的情况是,库存没有减少,而订单依然会生成。那我们如果增加了 Seata 来管理全局事务,情况是否会有所改变?我们测试如下:
库存服务已经了异常:

看下数据库数据:
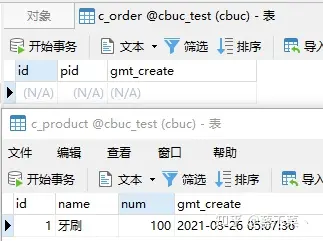
看样子我们全局事务已经生效了,事务也已经完美的控制住了!
而我们创建的 undo_log 这张表在管理事务中也启动了重要的作用:

看完了以上操作,我们趁热打铁来梳理一下其中的执行流程,让你印象更加深刻些~
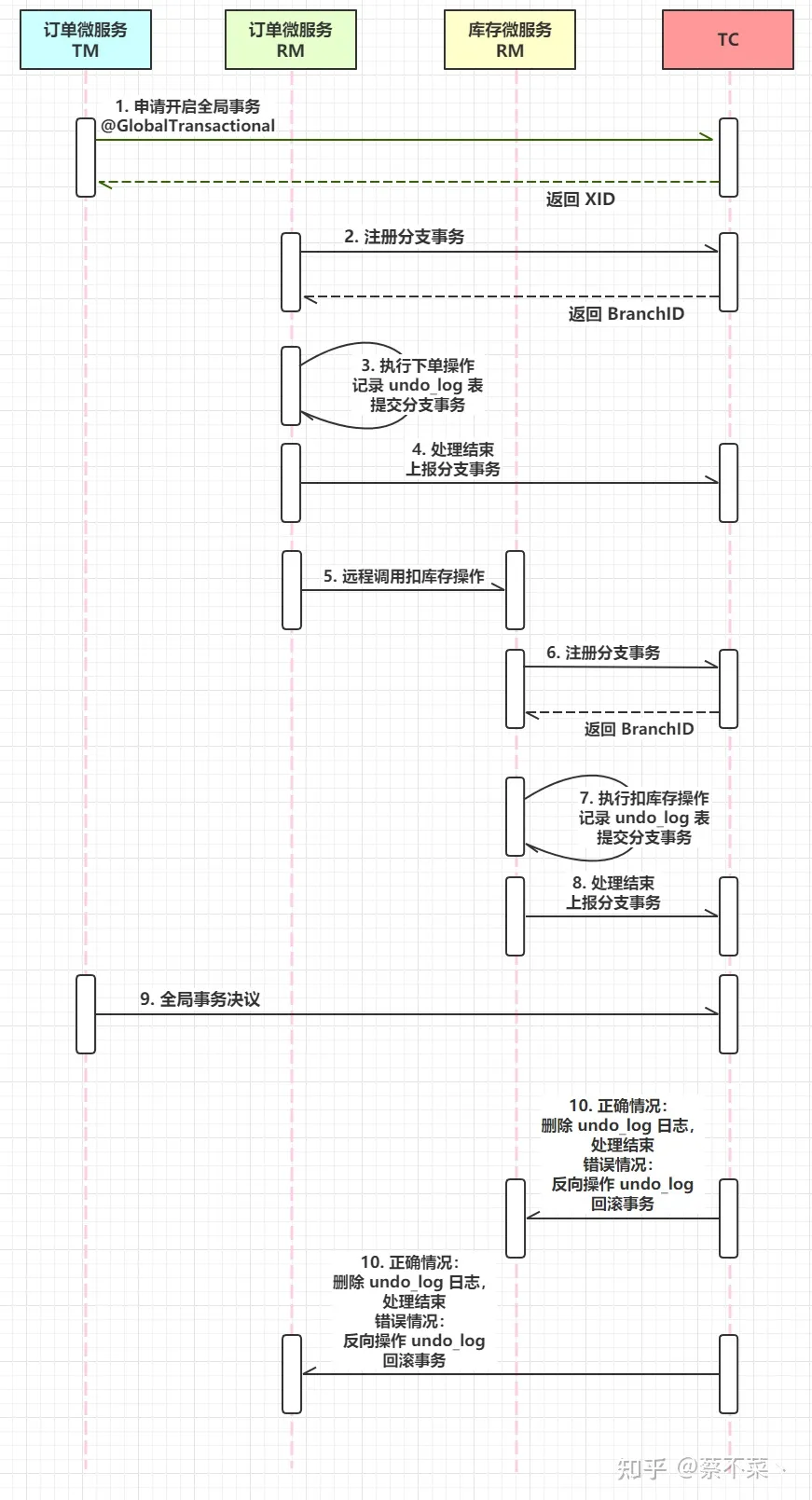
相信看完这张图,你对 Seata 执行事务的流程也更加熟悉了吧!
这还没结束,我们接着来看看其中的一些要点:
- 每个 RM 都需要使用 DataSourceProxy 连接数据库,这样是为了使用 ConnectionProxy,使用数据源和数据连接代理的目的就是在第一阶段将 undo_log 和业务数据放在一个本地事务提交,这样就保存了只要有业务操作就一定有 undo_log 产生!
- 在第一阶段的 undo_log 中存放了数据修改前和修改后的值,为事务回滚做好准备,所以第一阶段就已经将分支事务提交,也就释放了锁资源!
- TM 开启全局事务后,便会将 XID 放入全局事务的上下文中,我们通过 feign 调用也会将 XID 传入下游服务中,每个分支事务都会将自己的 Branch ID 与 XID 相关联!
- 第二阶段如果全局事务是正常提交,那么TC 会通知各分支参与者提交分支事务,各参与者只需要删除对应的 undo_log 即可,并且可以异步执行!
- 第二阶段如果全局事务需要回滚,那么 TC 会通知各分支事务参与者回滚分支事务,通过 XID 和 Branch ID 找到相应的 undo_log 日志,通过回滚日志生成反向 SQL 并执行,完成事务提交之前的状态,如果回滚失败便会重试回滚操作!
Reference
【分布式】1、CAP 理论 | 一致性、可用性、分区容忍性_呆呆的猫的博客-CSDN博客
数据库的CAP理论:一致性、可用性以及分区容忍性_数据库cap_东南门吹雪的博客-CSDN博客
Is CAP Theorem Still Relevant?
What is a two phase commit / XA transaction | XENOVATION ~ 什麼是兩階段提交/XA 事務 |異化
X/Open XA - Wikipedia ~ X/Open XA - 維基百科
Distributed Systems 7.1: Two-phase commit - YouTube
一文快速上手 Nacos 注册中心+配置中心! - 掘金 (juejin.cn)
Nacos启动报错:java.net.UnknownHostException: jmenv.tbsite.net_Cx_轩的博客-CSDN博客
从分布式事务解决到Seata使用,一梭子给你整明白了 - 知乎 (zhihu.com)